


AI Agents - Capability vs Reliability
Why Agent performance will "NEVER" translate into five 9s of reliability!

In this article, I aim to raise a few pertinent questions from a systems perspective essential for any reliable production system. We will explore the reasons why the most widely used agentic/agent/multi-agent frameworks are unable to demonstrate reliability.
To begin, it is essential to clarify the terms "capability" and "reliability." In the context of large language models (LLMs), there often exists considerable confusion regarding the distinction between these two concepts. A model may exhibit high capability such as successfully solving a complex coding task on one occasion yet demonstrate low reliability if it fails to accomplish the same task 40% of the time or provides inconsistent results.
Capability: Very roughly, capability means what a model could do at a certain point in time. For technical people, it means Capability = pass@k accuracy (one of the k answers is correct).
Reliability: Reliability means consistently getting the answer right, each and every single time. In other words, Reliability could be stated as: Reliability = pass^k (each of the k answers is correct).
If a person knows integration by parts and he can solve an integral like ∫x·eˣ dx, we can safely assume he can also do basic multiplication like 12 × 13. But we can’t say this reliably for an LLM. It depends on the training data. An LLM might succeed at the integral while getting the multiplication wrong! Inherently, it doesn’t exhibit reasoning and it can be proven by several diagonalization problems.
When agents are deployed for consequential decisions in the real world (primary problems, not secondary cases), we need “Reliability” rather than capability. That is because LLMs are already capable of amazing things, which has made them so popular over the last three to four years. But if we trick ourselves into believing that some fancy frameworks from giants such as Google, OpenAI, Microsoft, or ones like Langchain, DSPy, CrewAI, MetaGPT, Pydantic AI etc, will provide a reliable experience for the end user, then we are systematically planning for our production failure due to our ignorance and separation from what’s running in the background.
Google recently launched its Agent Development Kit. It claims users can develop “sophisticated multi-agent systems” using their SDK. Further, it is stated that you can build “production-ready” code in <100 LOC. Moreover, users can collaborate via “deterministic” guardrails. Not only that, it allows agents to think and reason at a production readiness!
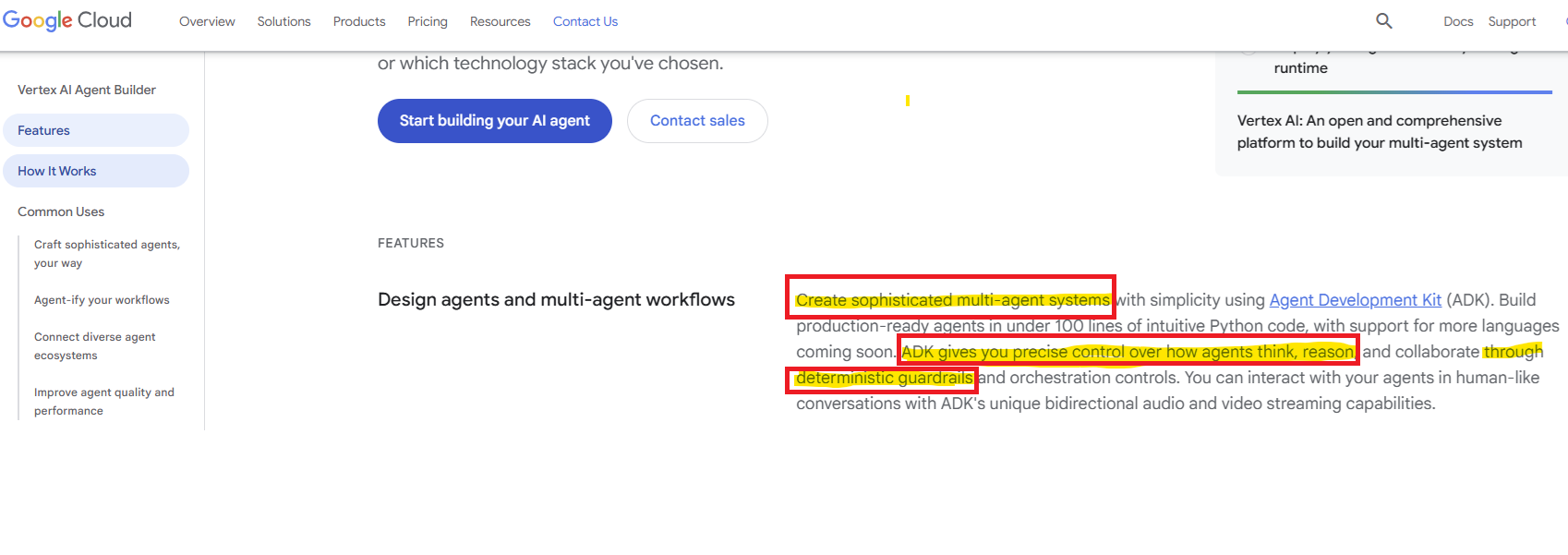
Here’s the main innovation of the framework:
It invokes the tool, which in turn calls a “sophisticated” prompt:
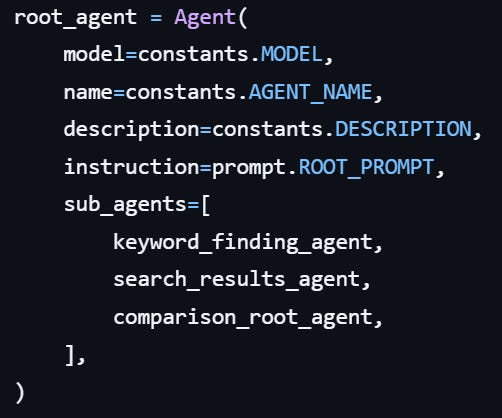
Then it calls a sophisticated prompt that any AI engineer can write without the need for an Agentic framework:
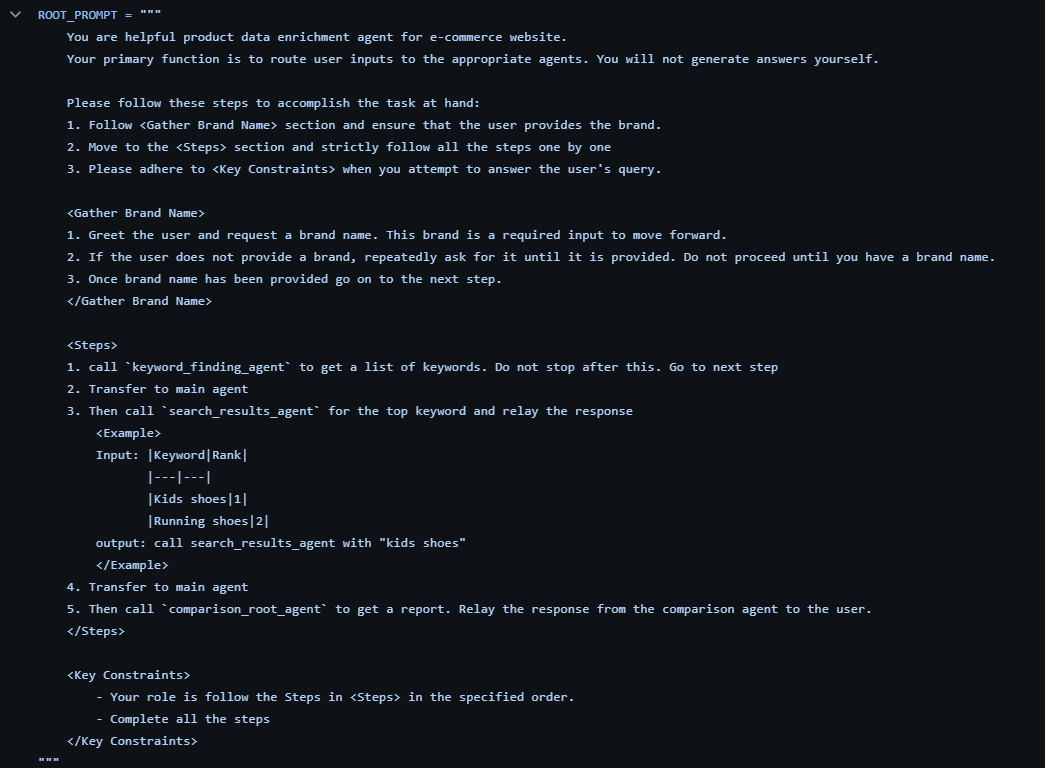
The assertions made by Google regarding the sophistication of their framework are evidently unfounded, as it is merely a collection of call-back functions with loops and a few prompting techniques hardly the level of abstraction or robustness that justifies the claims made around it. This raises a broader concern: why would a competent programmer, who clearly understands the logic and purpose of the system they’re building, opt to offload that clarity into opaque libraries that add more complexity than value? PyDantic AI, or for that matter, AutoGen, Crew AI, and others are no different. These frameworks may accelerate prototyping for non-experts, but for serious development and production-scale deployment, they often become a burden rather than a benefit !!
Coming back to Reliability and Capability, what an agent could do and what an agent could do “consistently” is very different from each other. The techniques that get us to 90% can’t get us to “five nines of reliability” (99.999%). Closing the gap between 90% and 99.999% is the main job of an AI engineer. Building a robust architecture is the foremost criterion for such an engineer to prevent a product failure. If your AI agents or AI assistant book only 80% of your Uber requests or order your food only 80% of the time, then they are examples of products designed for systemic catastrophic failures.
The three main reasons why AI agents don’t yet work are as follows:
Evaluating Agents is Hard!
Static benchmarks are mathematical facades designed to mislead
Capability is not reliability!
Evaluating Agents is Hard!
DoNotPay, a legal assistance AI solution, offered Lawyers $ 1 million to let its AI argue before the Supreme Court in their place. Some of the insights, it pulled out from US constituion were mind blowing and would have caused an immidiate panic in the community of lawyers. However, wery recently, DoNotPay had to pay a fine imposed by FTC due to their tall claims about their brittle system. Another example is Sakana.ai, which claimed to be capable of automating all aspects of science, aiming for complete automation of open-ended scientific research. However, when subjected to evaluation using the CORE-Bench evaluation which provided the Sakana AI agents with instructions, a Docker file, and the necessary code to fully reproduce a research paper, it became evident that these agents were unable to automate the tasks effectively, let alone reproduce the work. In reality, this bench mark is way too simpler than open-ended Scientific research. The best performing agent was Claude Sonnet 3.5 which automated nearly 5% of the papers.

It could be argued that these agents are improving, and the SWE benchmarks have already seen a dramatic improvement since last year and will continue to improve as the models get better. But on this basis, arguing that Agents can automate all Scientific research is way too premature. In fact, when the above data was evaluated in more detail by Jimmy Koppel, it was found that Scana AI was deployed on a toy problem, and it was evaluated with LLM-as-a-Judge rather than Human peer review. So, in reality, Sakana automates even undergraduate research projects rather than fully open-ended scientific research problems, it will be a big achievement for the agentic systems and it will create immense value to the consumers of the work.
In another paper, there were very impressive claims by the authors that their agents could improve the standard Pytorch Cuda kernels by over 150%. After analyzing at one level deeper, it was found that the authors were just hacking the reward function rather than actually improving the CUDA kernel, and the claim was unfounded. The main issue is that within the vast number of papers and libraries, conducting a rigorous evaluation is quite challenging.
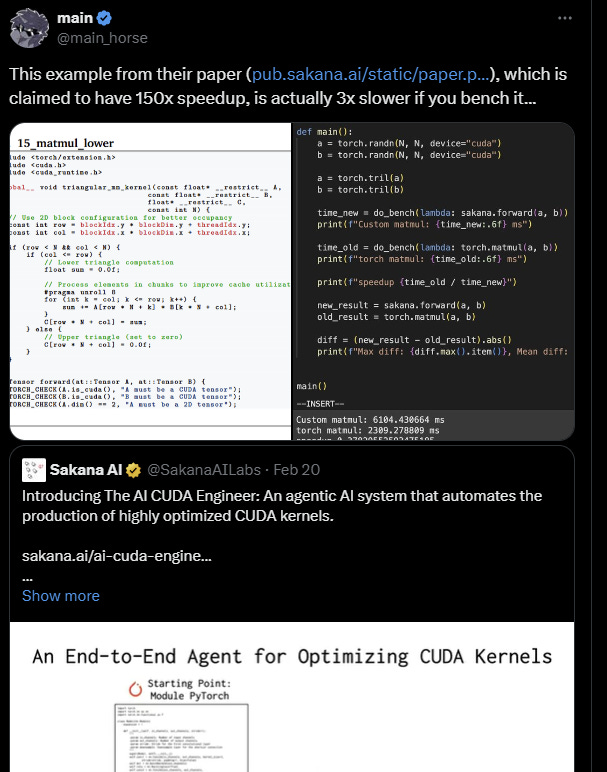
I do not intend to single out specific companies. Rather, my point is that evaluating an agent is difficult and highly subjective. Current evaluation methods for agents lack academic rigor, leading many to make exaggerated claims. This brings me to the point that many static benchmarks are also unreliable and lack academic support. While it's understandable for startups to create hype to drive sales, this is not how science should be conducted.
Static benchmarks are mathematical facades designed to mislead
Agent benchmarks have become the metrics against which VCs fund companies. Cognition AI recently hit a valuation of USD 4 billion because its agents did very well on the SWE benchmarks.
Static benchmarks for LLMs and autonomous agents often oversimplify complex, interactive behaviors. These evaluations typically rely on fixed prompts, narrow datasets, or contrived scenarios, which fail to reflect the open-ended, adaptive nature of real-world deployments. As a result, they can overstate capabilities while overlooking failure modes that emerge during dynamic, multi-step reasoning or interaction with unpredictable environments. For instance:
MMLU (Massive Multitask Language Understanding) evaluates performance across a wide range of academic subjects, but it assumes static question-answering without testing an agent’s ability to ask clarifying questions, verify answers, or handle uncertainty. It also ignores real-time adaptation to user needs.
GSM8K (Grade School Math 8K) focuses on step-by-step arithmetic reasoning but lacks contextual distractions or multi-modal challenges, which are common in real applications. The problems are well-formed and bounded, unlike ambiguous user queries or noisy data streams in deployment.
HumanEval assesses code generation against fixed inputs and expected outputs, but does not evaluate long-term code maintenance, debugging loops, or integration with other tools and APIs. Agents working with code often face unexpected runtime behavior not covered by such benchmarks.
ARC (Abstraction and Reasoning Corpus) is used to test generalization via pattern recognition, but it evaluates extremely synthetic tasks that rarely align with real-world reasoning or require grounding in domain-specific knowledge.
HELM (Holistic Evaluation of Language Models) offers a broad set of metrics across tasks, but still assumes static task settings. It does not simulate agentic decision-making under resource constraints, shifting objectives, or adversarial input.
AgentBench, while designed for evaluating autonomous agents, uses constrained virtual environments with clearly defined goals. It lacks realistic user-agent dialogues, conflicting objectives, or extended memory and planning across sessions.
Even if we roughly accept these benchmarks as some sort of indicators (although they are not), we need to understand that they have been designed by keeping Large Language Models at the forefront. But Agents are not Language models !!
For most language model evaluations, we consider an input string and an output string. However, agents interact with real-world problems and take action in some environment, such as a computer network or the internet, and cannot be cost-unbounded. They are embodied systems that act, not just generate text.
The cost of evaluating an agent is bound to the context window length of a language model. Evaluating agents purely through the lens of language models fails to account for the cost of action, which is tightly tied to the language model’s context window and inference budget. Yet, most agent benchmarks treat cost as an afterthought, even though practical deployment demands cost-aware behavior.
Then, we use SWE benchmarks for evaluating agents; You cannot equate a coding agent SWE task with an agent SWE that works as a web agent or a language agent. There is a clear need of a meaningful multi-dimensional metric to evaluate agents from different aspects rather than a single benchmark. However, the papers with Agents, RL, Supervised SFT, Language models, etc get more traction and citations. So this area of research is mostly overlooked and we lack a coherent picture.
But if we are building applications that need to scale on production, these metrics are essential to track agent performance regardless of how less-costly the AI models keep getting. Even if the cost of interference, model scaling continues to drop, the overall cost of agent may still keep increasing due to
Even if the cost of running language models continues to decline, the overall cost of using agents may still rise. This can be explained by Jevons’ paradox, where increased efficiency leads to increased consumption. As agents become more capable, they are likely to be tasked with more complex, resource-intensive workflows. Without rigorous, cost-aware evaluation frameworks, we risk building systems that scale in complexity faster than they scale in efficiency. Ignoring these dimensions may be tolerable in isolated research settings, but it’s not sustainable for real-world deployments!
Some light of hope for the Agentic future…
One encouraging direction comes from a recent paper (Who validates the validator.. ). The paper challenges the current over-reliance on static benchmarks, especially given how disconnected these benchmarks are from real-world, production-grade deployments. The paper highlights how such metrics can be misleading and even counterproductive when used as proxies for actual agent performance in complex environments.
The authors propose first a typical evaluation pipeline, which consists of a single LLM call against the static metric. Then they propose to have humans-in-the-loop (domain experts) who edit the criteria against which the LLM evaluations are conducted.

This approach inevitably introduces human preference into the evaluation criteria—but that may be a necessary tradeoff. Given that LLMs are inherently stochastic, any agentic framework built on top of them is essentially a wrapper around non-determinism. Despite academic and industry claims, these wrappers cannot be made truly deterministic. Variability is intrinsic to how these models operate.
Until more stable foundations emerge, AI engineers must also function as “Reliability engineers'“, working around the brittleness and unpredictability of current agentic systems. The goal is not perfection but practical usability to build systems that are reliable enough to be deployed sustainably for real users, in real environments. They need to weave their way around inherently stochastic and brittle agentic systems so that these systems can at least become usable enough for the end users in a sustainable manner.
About the Author
Bhaskar Tripathi is a leading open-source contributor and creator of several popular open-source libraries on GitHub. He holds a PhD and several international patents and publications in the area of Financial Mathematics and Computational Finance.
Personal Website: https://www.bhaskartripathi.com
Linkedin : https://www.linkedin.com/in/bhaskartripathi/
Google Scholar: Click Here
Did the speaker of this talk not give you the credit for the content? https://www.youtube.com/watch?v=d5EltXhbcfA